안녕하세요~ 저번 포스팅에 이어서 BeautifulSoup 사용법에 대해 추가로 포스팅 하겠습니다
저번에 우리는 대량의 페이지소스를 가져올 수 있게끔 하는 코딩을 연습했습니다
그 이후 이야기를 하기에 앞서서 페이지 소스가 무엇인지에 대해 간단하게 이야기를 해드리는게 좋겠습니다
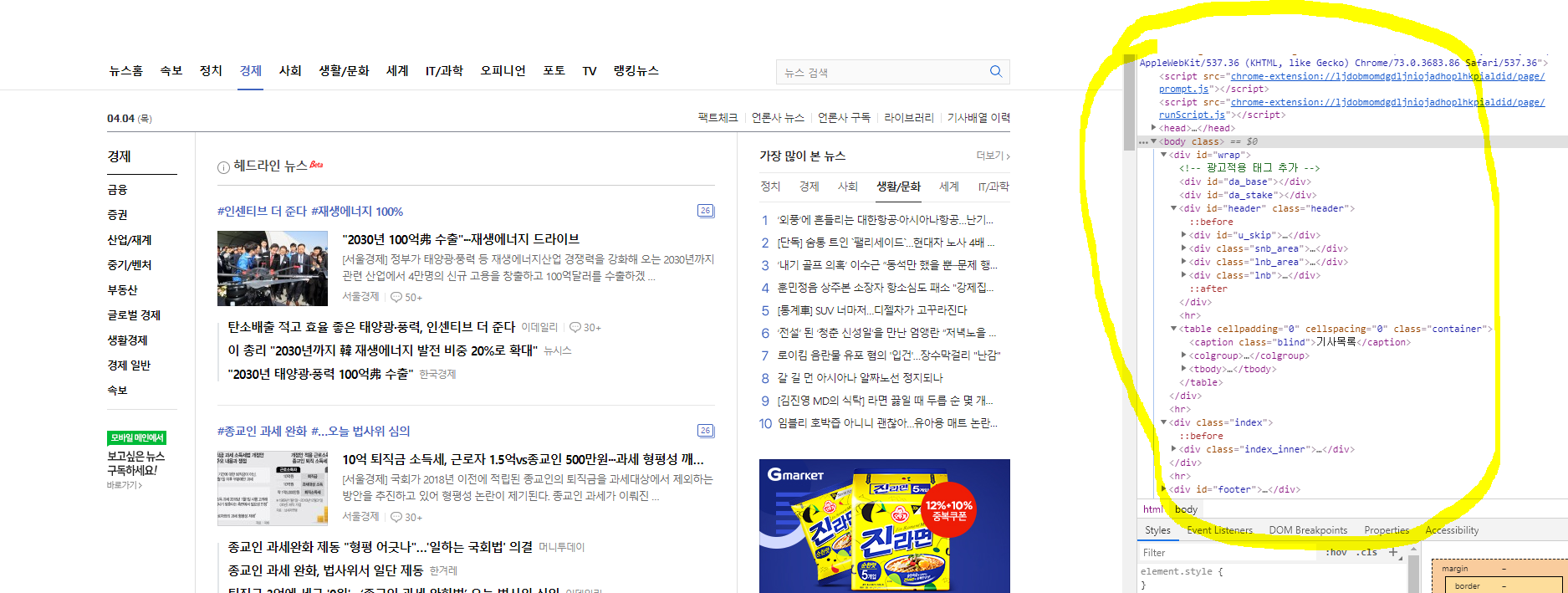
간단하게 말하자면 페이지를 구성하고 있는 내용들인거죠!
우리는 이 속에서 데이터를 가져오기 위해 필요한 내용을 가져올 수도 있고
바로 데이터를 가져올 수도 있습니다.
네이버 경제면 데이터 가져오기!
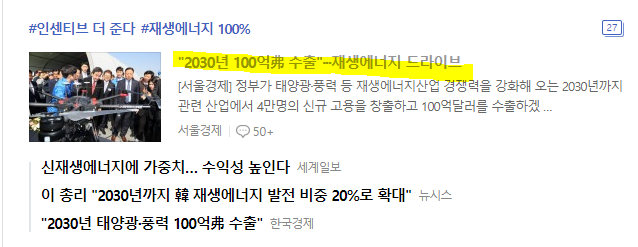
상단에 위치한 이 기사를 가져오려면 우리는 어떻게 하면 좋을까요?
방법은 이러합니다!
앞에서 말씀드린 페이지소스에서 기사로 들어가는 URL을 얻어 올 수 있습니다
( 위 페이지에서 기사로 들어갈 수 있으니까요! )
우리는 얻어온 URL을 가지고 저번 포스팅에서 사용했던 requests 함수에 다시 url을 붙여줄겁니다
그렇게 되면 해당 페이지의 내용을 가져올 수 있는 것 입니다
이제 앞에서 말로한 일 들을 직접 코드로 짜보겠습니다
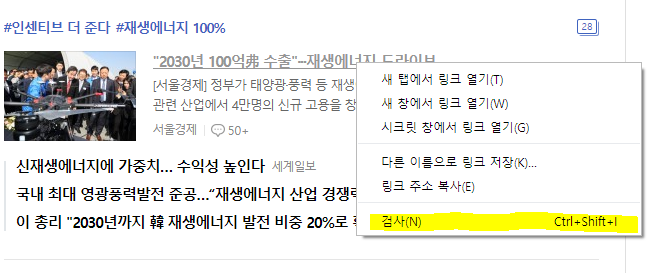
얻어오고자 하는 기사에 마우스 우클릭을 하여 '검사'를 클릭합니다
검사를 하면 우측에 페이지 소스가 나오면서 본인이 검사한 부분의 페이지 소스를 보여줍니다

저의 경우는 이렇게 떴네요! 직관적으로 앞에 보이는 url이
내가 얻고자 하는 데이터가 있는 페이지로 들어가는 url이라는 것을 알 수 있습니다
우리는 이 부분을 자동으로 가져오게끔 코딩을 짜야합니다
이 부분이 바로 오늘의 중점입니다
페이지소스 보고 경로 찾기( find, find_all )
페이지소스에는 정말 각양각색의 정보가 있습니다
우리는 그 중에서 우리가 원하는 정보만을 가져와야 합니다
우리는 원하는 정보를 찾을 수 있게 도와주는 find, find_all 함수를 사용할 겁니다
해당 함수는 BeautifulSoup에 내장되어 있는 함수입니다.
함수 설명 전, 페이지 소스 구성요소에 대해 간략히 말씀드리자면

빨간색 동그라미 부분이 태그입니다! div는 태그명 인거죠
파란색 동그라미 부분은 속성입니다! 속성값은 class가 아닌, 옆 부분의 노란 형광펜 부분입니다!!
마지막으로 분홍색(?) 밑줄 부분은 텍스트 부분입니다! 해당부분은 태그 a의 텍스트 부분이라고 말할 수 있겠네요
얻어오고자하는 정보를 정확히 얻어올 수 있는 능력이 있으면 웹 크롤링은 손쉽게 할 수 있다고 생각합니다
그러니 아래 부분에 설명 드릴 find, find_all 부분은 잘 봐두세요!
| find | 설명 |
|---|---|
| find('태그') | 해당 태그를 조건으로 가장 먼저 발견된 값 하나만 도출 |
| find('태그',{'속성':'속성값}) | 해당 태그 중에 같은 속성값을 가진 것 도출 |
| find('태그', 속성=True or False) | 해당 태그 중에서 해당 속성이 있는or 없는 것 |
| find_all | 설명 |
|---|---|
| find_all('태그') | 해당 태그를 조건으로 해당되는 모든 값 도출 |
| find_all('태그','속성값') | 태그와 속성값이 같은 모든 값 도출 |
| find_all('태그', 속성=True or False) | 해당 태그 중에서 해당 속성이 있는or 없는 것 |
이 외에도 정말 많은 방법이 있습니다. 우선 기본적이면서 많이 쓰이게 되는 것 위주로 정리했습니다
이제 이 방법들을 토대로 원하는 데이터를 파싱해오겠습니다
위에 있던 페이지소스를 보면 원하는데이터가 있는 곳은
a라는 태그이며 href와 class 라는 속성이 있습니다.
하나의 데이터를 찾을 때에는 위에 있는 "find('태그',{'속성':'속성값})" 를 사용하는 것이 가장 적합합니다
from bs4 import BeautifulSoup
import requests
url = "https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101#&date=%2000:00:00&page=101"
req = requests.get(url)
bs = BeautifulSoup(req.content.decode('utf-8', 'replace'), 'html.parser')
news= bs.find('a',{'class':'cluster_text_headline nclicks(cls_eco.clsart)'})
url_data=news.get("href")
갑자기 모르는 이야기들이 나왔을 겁니다
requests.get 은 requests에 있는 메서드로써 해당 url에 정보를 요청했다고 생각하시면 됩니다
BeautifulSoup는 바로 req에 요청한 정보들을 아까 보신 페이지소스 형태로 가져오는 것 입니다.
news는 가져온 페이지소스에서 앞서 설명한 방식으로 원하는 데이터를 가져 온 것이죠
get("herf")는 가져온 코드에서 herf의 속성값을 가져오는 것입니다
아래는 결과 값입니다
'https://news.naver.com/main/read.nhn?mode=LSD&mid=shm&sid1=101&oid=022&aid=0003352305'
우리는 해당경로에 들어가 다시 같은 방법으로 정보를 가져올 것입니다

결과값을 url에 입력했더니 다행히도 동일한 기사 제목이 나옵니다
각자 얻고자 하는 내용이 다르겠지만
저는 본문정보를 가져와 보겠습니다! 방법은 동일합니다
본문을 검사 하여 어디에 원하는 데이터가 있는지 파악 후 가져오는 것입니다

내용이 상당히 복잡한 듯 보이지만 실상은 그렇지 않습니다
해당 페이지소스의 경우, 페이지의 생김새와 유사하게
중간중간에 이미지 관련 소스가 들어가있는 것 뿐입니다
코드는 다음과 같습니다
req= requests.get(url_data)
bs = BeautifulSoup(req.content.decode('euc-kr','replace'), 'html.parser')
news= bs.find('div',{'id':'articleBodyContents'})
data=news.get_text()
str(data)
req에 들어가는 변수가 위에서 뉴스기사 주소를 저장했던 변수로
news의 경우, 제가 본문 전체를 포함하는 태그와 속성, 속성값으로 변환 되었습니다
get_text는 news에서 가져왔던 소스중에서 텍스트 부분을 가져오라는 이야기 입니다!
그리고 한글이 깨져 decode를 위에 써있는 것으로 바꾸었습니다.
아래는 결과입니다
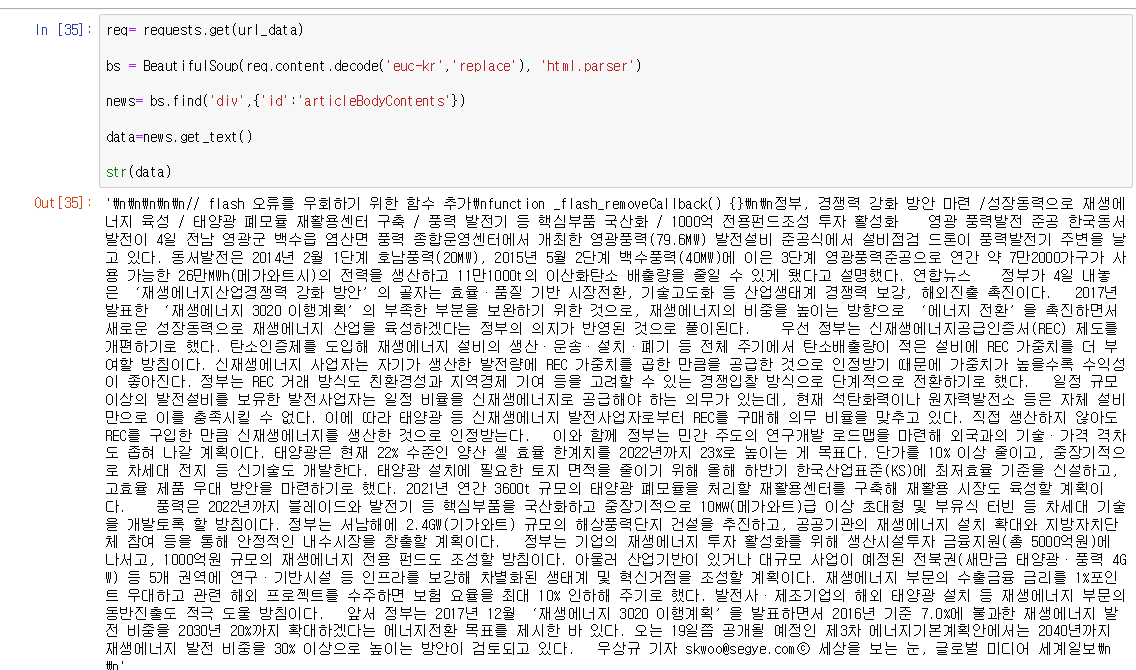
본문이 잘 들어간 것을 확인 할 수 있었습니다
이런 방식으로 for문을 활용하여 자동으로 데이터를 가져 올 수 있습니다!
find, find_all의 경우 위에 써있는 방법 이외에도 다양한 방법이 많이 있습니다.
뿐만 아니라 select 라는 함수를 이용하여 경로를 표시하는 selector 도 있습니다.
그렇기 때문에 해당 부분은 제가 관련 게시물을 쓰기 전까지는.... 다른 블로그나 사이트에서 필독하셔야 합니다!
또, 찾는 부분이 명확한 경우 검사버튼 클릭 후, 해당 소스를 우클릭 하여 copy를 통해 경로를 가져 올 수도 있습니다
그러나, 유용함 면에서는 find, find_all 등을 통해 직관적으로 찾는 것이 훨씬 도움이 된다고 생각합니다
모두들 화이팅 하시길 바라겠습니다~~!!
'Python > 크롤링' 카테고리의 다른 글
| 초보자의 크롤링 도전기!!(3) - Selenium (3) | 2019.04.06 |
|---|---|
| 초보자의 크롤링 도전기!!(1) - BeautifulSoup (0) | 2019.04.03 |